GPTchat peut-il vous aider à passer un test python ?
2022-12-21 - guiral Lacotte
“Vous rêvez de décrocher votre prochain emploi dans le monde de la technologie, mais vous êtes stressé à l’idée de devoir passer un test de programmation en Python? Ne paniquez pas! Dans cet article, je vous raconte comment j’ai utilisé GPT-3, l’un des modèles de traitement du langage naturel les plus avancés au monde, pour réussir haut la main un test de programmation en Python lors d’un entretien d’embauche. Suivez mes conseils et vous serez prêt à affronter n’importe quel test de programmation en toute confiance.” – ChatGPT
Je perdais mon temps sur Twitter lorsque je suis tombé sur ce tweet qui proposait de passer un test en Python qui serait représentatif de ce qui pourrait être demandé lors d’un entretien d’embauche. L’exercice consistait à implémenter un interpréteur BrainFuck, un langage de programmation étrange et volontairement incompréhensible. L’exercice était interessant, je n’avais jamais codé d’interpreteur j’ai décidé de relever le défi.
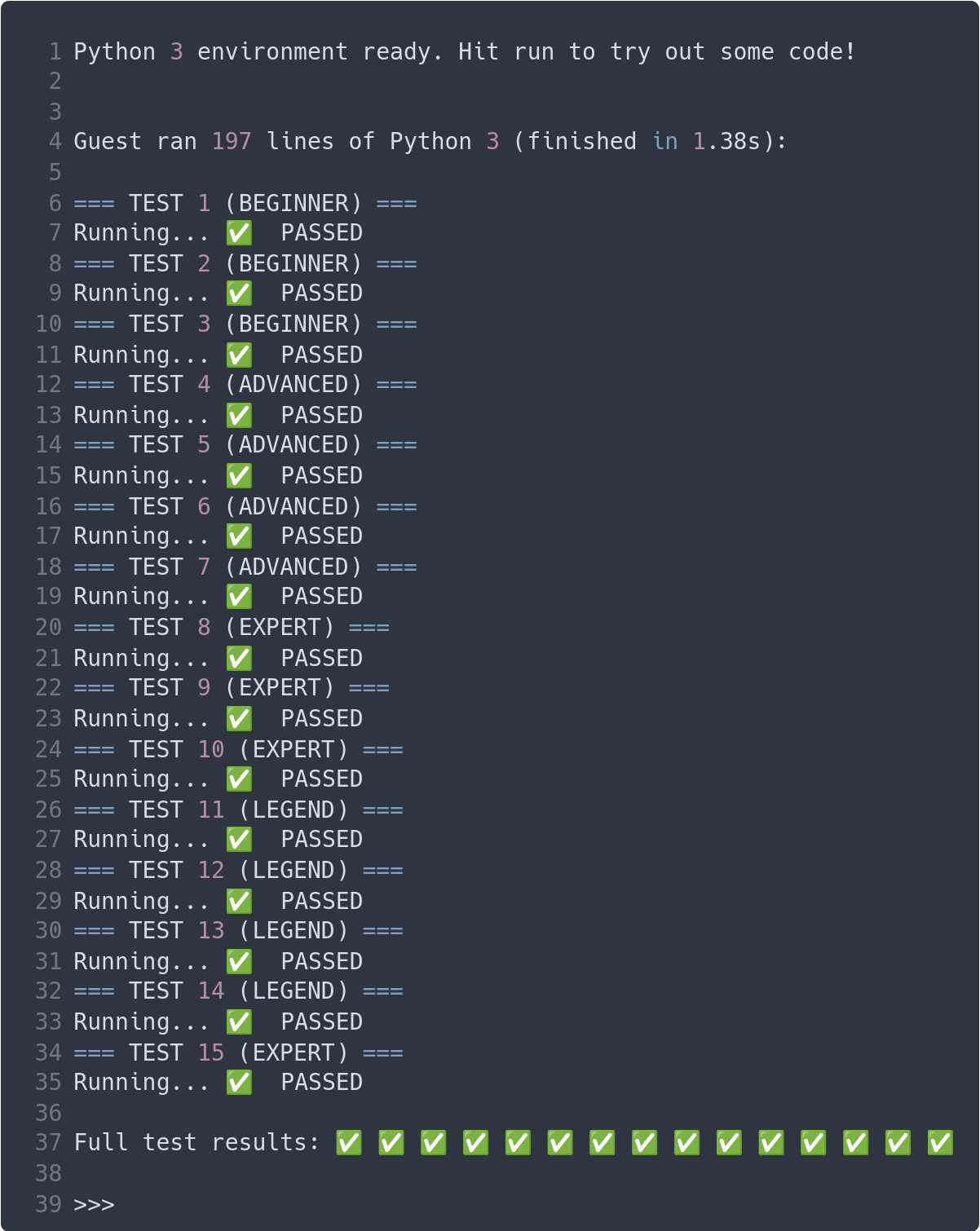
Après quelques recherches sur GitHub, j’ai trouvé un interpréteur BF en Python 3 déjà fonctionnel. Je l’ai copié-collé sur la page coderpad.io et j’ai effectué quelques modifications pour utiliser les bons tampons. Lorsque j’ai lancé l’évaluation, j’ai obtenu un score modeste de 6 sur 15. J’ai passé un peu plus de temps sur le problème en fin de journée et j’ai obtenue le 15 sur 15. Fin de l’histoire tout le monde s’en fout.
Les choses interessante arrivent après, je poste donc fièrement mon résultat sur Twitter. Parmi les nombreuses réponses au tweet original, l’une d’elles attire mon attention.
“NUL pour un entretien
Déjà chatgpt va le coder à sa place
Ensuite python pour faire des algos de ce type c’est juste pas le bon langage Ensuite tu demandes au dev plusieurs centaines de lignes alors qu’un dev ça code 10 lignes par jour Puis demander un algo étudient à un pro 😑” –@dededede4
Lors de mes précédents tests j’ai pue vérifier qu’il était déjà tout à fait possible de tricher en utilisant des outils comme GitHub Copilot, mais cela nécessite des connaissances en programmation. Mon idée et défi consiste à essayer de produire une solution sans écrire moi-même une seule ligne de code, voire sans apporter aucune modification. Le NoCode est à la mode, c’est l’occasion de tester.
Voici les règles du défi:
- Le résultat doit être obtenu à partir d’une seule demande à GPT-3/ChatGPT.
- La demande doit être faite en français.
- La demande doit être effectuée dans une nouvelle conversation.
Approche naïve
Requette:Je voudrais un interpreteur brainfuck en python 3.
Résultat:
#!/usr/bin/env python3
import sys
def run_bf(bf_code, input_str):
input_chars = list(input_str)
input_len = len(input_chars)
input_index = 0
# Initialise la mémoire à zéro
memory = [0]
pointer = 0
# Initialise la sortie à une chaîne vide
output = ""
# Itère sur chaque caractère du code Brainfuck
for c in bf_code:
if c == ">":
# Incrémente le pointeur de mémoire
pointer += 1
if pointer == len(memory):
memory.append(0)
elif c == "<":
# Décrémente le pointeur de mémoire
pointer -= 1
elif c == "+":
# Incrémente la valeur à l'emplacement de mémoire actuel
memory[pointer] = (memory[pointer] + 1) % 256
elif c == "-":
# Décrémente la valeur à l'emplacement de mémoire actuel
memory[pointer] = (memory[pointer] - 1) % 256
elif c == ".":
# Ajoute la valeur de l'emplacement de mémoire actuel à la sortie
output += chr(memory[pointer])
elif c == ",":
# Lit un caractère de l'entrée et le stocke à l'emplacement de mémoire actuel
if input_index < input_len:
memory[pointer] = ord(input_chars[input_index])
input_index += 1
else:
memory[pointer] = 0
elif c == "[":
# Si la valeur de l'emplacement de mémoire actuel est nulle, saute au caractère de fermeture de la boucle
if memory[pointer] == 0:
loop_count = 1
while loop_count > 0:
c = bf_code[i]
i += 1
if c == "[":
loop_count += 1
elif c == "]":
loop_count -= 1
elif c == "]":
# Si la valeur de l'emplacement de mémoire actuel n'est pas nulle, saute au caractère d'ouverture de la boucle
if memory[pointer] != 0:
loop_count = 1
while loop_count > 0:
c = bf_code[i]
i -= 1
if c == "[":
loop_count -= 1
elif c == "]":
loop_count += 1
return output
def main():
# Vérifie qu'un fichier a été passé en argument
if len(sys.argv) != 2:
print("Utilisation: bf.py fichier.bf")
GPT-3 nous donne un interpréteur BF fonctionnel qui semble avoir été copié-collé depuis un dépôt quelconque, mais c’est un bon début.
30 minutes plutard
Requete: Je voudrai un interpreteur brainfuck en python 3 sous la forme d’une fonction qui prend en entrer le code sous la forme d’un array nomé brainfuck_code et les entrées utilisateurs sous la forme d’un array nomé def solution user_input. La mémoire est cyclique et fait 30000 cellules. Les entrée mémoire sont des bytes non signés.
Résultat:
Voici comment vous pourriez écrire une fonction en Python 3 qui interprète du code Brainfuck. Cette fonction prend en entrée une chaîne de caractères représentant le code Brainfuck et une chaîne de caractères représentant les entrées utilisateur, et retourne une chaîne de caractères représentant la sortie générée par le code Brainfuck:
def interpret_brainfuck(brainfuck_code, user_input):
# Créer une liste de 30000 bytes non signés pour la mémoire
memory = [0] * 30000
# Initialiser les variables d'instruction et de pointeur de mémoire
instruction_ptr = 0
memory_ptr = 0
# Initialiser la sortie à une chaîne vide
output = ""
# Initialiser l'index de l'entrée utilisateur à 0
input_idx = 0
# Répéter jusqu'à ce que l'instruction pointée soit "EOF" (fin de fichier)
while brainFuck_code[instruction_ptr] != "EOF":
# Récupérer l'instruction actuelle
instruction = brainFuck_code[instruction_ptr]
# Exécuter l'instruction en fonction de sa valeur
if instruction == ">":
# Incrémenter le pointeur de mémoire
memory_ptr += 1
elif instruction == "<":
# Décrémenter le pointeur de mémoire
memory_ptr -= 1
elif instruction == "+":
# Incrémenter la valeur de la cellule de mémoire pointée
memory[memory_ptr] += 1
elif instruction == "-":
# Décrémenter la valeur de la cellule de mémoire pointée
memory[memory_ptr] -= 1
elif instruction == ".":
# Ajouter la valeur de la cellule de mémoire pointée à la sortie
output += chr(memory[memory_ptr])
elif instruction == ",":
# Lire l'entrée utilisateur et affecter sa valeur à la cellule de mémoire pointée
memory[memory_ptr] = ord(user_input[input_idx])
input_idx += 1
elif instruction == "[":
# Si la valeur de la cellule de mémoire pointée est 0, sauter à la correspondance de "]"
if memory[memory_ptr] == 0:
instruction_ptr = brainFuck_code.index("]", instruction_ptr)
elif instruction == "]":
# Si la valeur de la cellule de mémoire pointée n'est pas 0, retourner à la correspondance de "["
if memory[memory_ptr] != 0:
instruction_ptr = brainFuck_code.index("[", 0, instruction_ptr)
# Passer à l'instruction suivante
instruction_ptr += 1
Le code comprend des commentaires en français, ce qui est positif. GPT-3 a également respecté la demande de produire une fonction et de donner des noms de variables appropriés. Cependant, il y a quelques points à améliorer:
- La fonction ne retourne pas de valeur de sortie.
- La mémoire n’est pas implémentée de manière cyclique (elle ne retourne pas à zéro une fois qu’elle atteint la fin de la liste).
- Les entrées ne sont pas traitées comme des entiers, mais comme des chaînes de caractères.”
Après avoir effectué plusieurs tests, j’ai constaté que dans sa version d’essai gratuite, GPT-3 tronquait les réponses qui étaient trop longues lorsque le service était surchargé, ce qui expliquait l’absence de retour de la fonction plutôt qu’un oubli réel de la part du système. On abandonne le code doit être généré en une seul fois.
Requete: la fonction doit retourner la sortie.
Réponse: Pour retourner la sortie générée par le code Brainfuck, il suffit de retourner la chaîne de caractères output à la fin de la fonction interpret_brainFuck. Voici comment la fonction complète pourrait ressembler: …
Requete: La mémoire doit être cyclique.
Réponse: Pour que la mémoire soit cyclique dans l’interpréteur BrainFuck que j’ai proposé, vous pouvez ajouter un modulo 30000 aux opérations d’incrémentation et de décrémentation du pointeur de mémoire. Cela permettra de s’assurer que le pointeur de mémoire reste compris entre 0 et 29999, ce qui correspond aux limites de la mémoire cyclique de 30000 cellules. Voici comment la fonction pourrait être modifiée pour prendre en compte la mémoire cyclique: …
Requete: Les cellules mémoires sont des entiers non signés compris entre 0 et 255.
Pour que les cellules de mémoire soient des entiers non signés compris entre 0 et 255, vous pouvez utiliser le type de données bytes de Python, qui est une séquence immutable d’octets. Vous pouvez créer une liste de 30000 octets non signés en utilisant la fonction bytes de Python et en initialisant chaque élément à 0. Voici comment la fonction interpret_brainFuck pourrait être modifiée pour utiliser des octets non signés pour les cellules de mémoire: …
C’est là que les choses deviennent intéressantes. Le commentaire introductif est plutôt juste, mais le code fourni ne le prend absolument pas en compte. Il recrache le code lors de l’étape précédente.
def interpret_brainFuck(brainFuck_code, user_input):
...
if instruction == ">":
# Incrémenter le pointeur de mémoire de manière cyclique
memory_ptr = (memory_ptr + 1) % 30000
elif instruction == "<":
# Décrémenter le pointeur de mémoire de manière cyclique
memory_ptr = (memory_ptr - 1) % 30000
elif instruction == "+":
# Incrémenter la valeur de la cellule de mémoire pointée
memory[memory_ptr] += 1
elif instruction == "-":
# Décrémenter la valeur de la cellule de mémoire pointée
memory[memory_ptr] -= 1
Requête: Les valeurs stockées en mémoires sont comprises entre 0 et 255. Réponse:Pour s’assurer que les valeurs stockées en mémoire restent comprises entre 0 et 255, vous pouvez utiliser l’opérateur modulo % dans les opérations d’incrémentation et de décrémentation des cellules de mémoire. Cela permettra de limiter les valeurs des cellules de mémoire à l’intervalle [0, 255]. Voici comment la fonction interpret_brainFuck pourrait être modifiée pour limiter les valeurs des cellules de mémoire à l’intervalle [0, 255]:
def interpret_brainFuck(brainFuck_code, user_input):
...
# Exécuter l'instruction en fonction de sa valeur
if instruction == ">":
# Incrémenter le pointeur de mémoire de manière cyclique
memory_ptr = (memory_ptr + 1) % 30000
elif instruction == "<":
# Décrémenter le pointeur de mémoire de manière cyclique
memory_ptr = (memory_ptr - 1) % 30000
elif instruction == "+":
# Incrémenter la valeur de la cellule de mémoire pointée de manière modulaire
memory[memory_ptr] = (memory[memory_ptr] + 1) % 256
elif instruction == "-":
# Décrémenter la valeur de la cellule de mémoire pointée de manière modulaire
memory[memory_ptr] = (memory[memory_ptr] - 1) % 256
elif instruction == ".":
Au final, j’ai obtenu un code qui fonctionne, mais qui ne passe que 6 tests sur 15. Ce qui n’est pas trop mal si l’on considère que je n’ai écrit aucune ligne de code moi-même. J’ai refait l’exercice en anglais. Cette fois-ci GPT-3 s’en sort beaucoup mieux. Le temps de traitement était plus court, ce qui a permis de réduire les problèmes de troncature des réponses (probablement dus à un délai d’expiration) et il a mieux intégré les remarques. Le code suivant a obtenu un score de 8 sur 15 lors du test initial.
def solution(code, user_input):
memory = [0] * 30000 # Memory with 30,000 cells, initialized to 0
# Pointer to current cell in memory
ptr = 0
# Index of the current input character
input_index = 0
# Output string
output = ''
# Loop through each character in the code
i = 0
while i < len(code):
# Get the current character and move to the next
char = code[i]
i += 1
if char == '>':
# Increment the pointer, wrapping around if necessary
ptr = (ptr + 1) % len(memory)
elif char == '<':
# Decrement the pointer, wrapping around if necessary
ptr = (ptr - 1) % len(memory)
elif char == '+':
# Increment the value at the current cell, wrapping around if necessary
memory[ptr] = (memory[ptr] + 1) % 256
elif char == '-':
# Decrement the value at the current cell, wrapping around if necessary
memory[ptr] = (memory[ptr] - 1) % 256
elif char == '.':
# Append the character with the ASCII value of the current cell to the output string
output += chr(memory[ptr])
elif char == ',':
# Input a character from the user_input list and store its ASCII value in the current cell
memory[ptr] = ord(user_input[input_index])
input_index += 1
elif char == '[':
# If the value at the current cell is 0, jump to the corresponding ']'
if memory[ptr] == 0:
loop = 1
while loop > 0:
char = code[i]
i += 1
if char == '[':
loop += 1
elif char == ']':
loop -= 1
elif char == ']':
# If the value at the current cell is not 0, jump back to the corresponding '['
loop = 1
while loop > 0:
i -= 1
char = code[i]
if char == '[':
loop -= 1
print('Output :', output)
return output
Détecter les IA avec Python 3.10
GPT-3 ne connait que python jusqu’à la version 3.8, si on lui demande d’utiliser la fonction match/case introduite dans python 3.10 il perd les pédales et nous raccompte n’importe quoi.
Q: Pourrais-tu utiliser match case à la place de if elif ?
R: Oui, vous pouvez utiliser un dictionnaire et la fonction get pour remplacer les structures if et elif dans la fonction interpret_brainFuck. Le dictionnaire sera utilisé pour associer chaque instruction BrainFuck à une fonction qui effectue l’opération correspondante. Voici comment la fonction interpret_brainFuck pourrait être modifiée pour utiliser un dictionnaire et la fonction get:
def interpret_brainFuck(brainFuck_code, user_input):
...
operations = {
">": lambda: setattr(memory_ptr, (memory_ptr + 1) % 30000),
"<": lambda: setattr(memory_ptr, (memory_ptr - 1) % 30000),
"+": lambda: setattr(memory[memory_ptr], (memory[memory_ptr] + 1) % 256),
"-": lambda: setattr(memory[memory_ptr], (memory[memory_ptr] - 1) % 256),
".": lambda: setattr(output, output + chr(memory[memory_ptr])),
",": lambda: setattr(memory[memory_ptr], ord(user_input[input_idx])),
"[": lambda: setattr(instruction_ptr, brainFuck_code.index("]", instruction_ptr))
if memory[memory_ptr] == 0 else None,
"]": lambda: setattr(instruction_ptr, brainFuck_code.index("[", 0, instruction_ptr))
if memory[memory_ptr] != 0 else None,
}
# Répéter jusqu'à ce que l'instruction pointée soit "EOF" (fin de fichier)
while brainFuck_code[instruction_ptr] != "EOF":
# Récupérer l'instruction actuelle et exécuter l'opération correspondante
operations.get(brainFuck_code[instruction_ptr], lambda: None)()
# Passer à l'instruction suivante
instruction_ptr += 1
# Retourner la sortie générée par le code BrainFuck
return output
Dans cette version de la fonction, chaque instruction BrainFuck est associée à une fonction lambda qui effectue l’opération correspondante. Lorsque l’instruction est exécutée, la fonction lambda est appelée en utilisant la méthode get du dictionnaire ‘operations’.
Utiliser un dictionnaire de fonctions pourrait être une solution élégante pour résoudre ce problème, mais le code part complètement en vrille et définit des lambda avec des setattr avec deux arguments au lieu de trois. Ensuite, il attend un EOF sur un tableau. Si vous voulez casser GPT-3, demandez-lui de coder en Python 3.10.
Conclusion
En conclusion, est-ce que GPT-3 permet de tricher lors d’un entretien en temps limité et est-ce que le NoCode et les intelligences artificielles vont mettre les développeurs au chômage? La réponse est non. Tout d’abord, dans sa version gratuite, GPT-3 est assez lent à répondre. J’ai mis moins de temps à trouver un dépôt GitHub en utilisant Google qu’à attendre la réponse de GPT-3 lorsque j’ai fait la demande en français. Sans une compréhension fine des problémes les résultats fournis sont inexploitables. Il est difficile et inefficace de lui faire prendre en compte des détails d’implémentation tels que le bouclage mémoire ou certains comportements (débordement d’entier) lorsqu’on l’interroge en anglais, et presque impossible lorsqu’on l’interroge en français. Il sort n’importe quoi dès qu’on lui demande de coder dans un langage qui sort un peu de sa base d’apprentissage. Il pourrait être intéressant de comparer ses performances en fonction des langages et de leur popularité. Les résultats restent tout de même beaucoup plus impressionnants que la majorité de outils “NoCode” qui tiennent plus du légo, programmation visuel.
TL;DR : GPT-3 peut sortir du code identique à une bonne recherche google sur github, il peut commenter le code et le traduire, voir faire quelques modifications mineurs comme les noms de variables. Mais il est très difficile de lui faire faire plus de chose et c’est probablement plus lent que de le faire soit même. Si vous savez coder Github Copilot fait mieux.

 J’ai donc acheté par la même occasion un boîtier Miche Evo Max au format BSA 68mm (les cadres piste reprennent le standard route). Premières constations le boîtier fait plutôt bas de gamme, les flasques sont en aluminium non anodisé et ne comportent aucune indication de montage. Les indications droite, gauche et le sens de serrage auraient été des miniums.
J’ai donc acheté par la même occasion un boîtier Miche Evo Max au format BSA 68mm (les cadres piste reprennent le standard route). Premières constations le boîtier fait plutôt bas de gamme, les flasques sont en aluminium non anodisé et ne comportent aucune indication de montage. Les indications droite, gauche et le sens de serrage auraient été des miniums. En ces temps de confinement Covid-19, j’ai enfin prit le temps d’effectuer quelques projet que j’avais dans mes calpins depuis un certain temps. L’un d’eux etait d’effectuer un maximum de demandes d’accès à mes données personnels via la
En ces temps de confinement Covid-19, j’ai enfin prit le temps d’effectuer quelques projet que j’avais dans mes calpins depuis un certain temps. L’un d’eux etait d’effectuer un maximum de demandes d’accès à mes données personnels via la